
Scrapy部署
将Scrapy项目放在个主机上运行时,如果我们采用的文件上传或Git同步的方式,这样需要各台主机都进行操作,如果有100台,1000台主机,工作量可想而知。于是需要了解一下爬虫在部署方面可以采取的一些措施,以方便地实现爬虫任务的管理方案。本章主要介绍两种scrapy爬虫方案:基于Scrapyd的管理方案和Kuberbets的管理方案。
Scrapyd
Scrapyd是一个运行scrapy爬虫的服务程序,它提供了一系列HTTP接口来帮助我们部署、启动、停止和删除爬虫程序。Scrapyd支持版本管理,同时还可以管理多个爬虫任务。
Scrapyd的安装很简单:pip3 install scrapyd
配置
安装完毕之后需要新建一个配置文件 /etc/scrapyd/scrapyd.conf,Scrapyd 在运行的时候会读取此配置文件。
在 Scrapyd 1.2 版本之后不会自动创建该文件,需要我们自行添加。
执行命令新建文件:
1 | sudo mkdir /etc/scrapyd |
写入如下内容:
1 | [scrapyd] |
配置文件的内容可以参见官方文档:https://scrapyd.readthedocs.io/en/stable/config.html#example-configuration-file,在这里的配置文件有所修改,其中之一是 max_proc_per_cpu 官方默认为 4,即一台主机每个 CPU 最多运行 4 个 Scrapy Job,在此提高为 10,另外一个是 bind_address,默认为本地 127.0.0.1,在此修改为 0.0.0.0,以使外网可以访问。
后台运行
由于 Scrapyd 是一个纯 Python 项目,在这里可以直接调用 scrapyd 来运行,为了使程序一直在后台运行,Linux 和 Mac 可以使用命令:(scrapyd > /dev/null &),这样 Scrapyd 就会在后台持续运行了,控制台输出直接忽略,当然如果想记录输出日志可以修改输出目标,如:(scrapyd > ~/scrapyd.log &),则会输出 Scrapyd 运行输出到~/scrapyd.log 文件中。运行之后便可以在浏览器的 6800 访问 WebUI 了,可以简略看到当前 Scrapyd 的运行 Job、Log 等内容。

当然运行 Scrapyd 更佳的方式是使用 Supervisor 守护进程运行,如果感兴趣可以参考:http://supervisord.org/。
访问认证
限制配置完成之后 Scrapyd 和它的接口都是可以公开访问的,如果要想配置访问认证的话可以借助于 Nginx 做反向代理,在这里需要先安装 Nginx 服务器。
在此以 Ubuntu 为例进行说明,安装命令如下:
1 | sudo apt-get install nginx |
然后修改 Nginx 的配置文件 nginx.conf,增加如下配置:
1 | http { |
在这里使用的用户名密码配置放置在 /etc/nginx/conf.d 目录,我们需要使用 htpasswd 命令创建,例如创建一个用户名为 admin 的文件,命令如下:
1 | htpasswd -c .htpasswd admin |
接下就会提示我们输入密码,输入两次之后,就会生成密码文件,查看一下内容:
1 | cat .htpasswd |
配置完成之后我们重启一下 Nginx 服务,运行如下命令:
1 | sudo nginx -s reload |
这样就成功配置了 Scrapyd 的访问认证了。
Scrapyd的功能
Scrapyd提供了一系列的HTTP接口来实现各种操作。
daemonstatus.json
该接口负责查看Scrapyd当前的服务和任务状态,可以用curl命令来请求这个接口。具体如下:
1 | curl http://localhost:6800/daemonstatus.json |
如果加了nginx认证的话则,
1 | curl -u yourusername:yourpassword http://localhost:6800/daemonstatus.json |
示例响应:
1 | { "status": "ok", "running": "0", "pending": "0", "finished": "0", "node_name": "node-name" } |
addversion.json
这个接口主要用来部署scrapy项目。在部署的时候,我们需要先将项目打包成egg文件,然后传入项目名称和部署版本。
1 | $ curl http://localhost:6800/addversion.json -F project=<myproject> -F version=V1 -F egg=@<myproject>.egg |
这里的-F即代表添加一个参数,同时我们还需要将项目打包成egg文件放到本地。
不过使用此方法部署比较繁琐,后文会有更方便的工具来实现项目的部署。
示例响应:
1 | {"status": "ok", "spiders": 3} |
schedule.json
部署完成之后,项目其实就存在于Scrapyd之上,那么怎么来运行Scrapy项目呢?此时需要借助schedule.json这个接口,它负责调度已部署好的Scrapy项目。
具体实现如下:
1 | curl http://localhost:6800/schedule.json -d project=<myproject> -d spider=<myspider> |
起类似于执行:scrapy crawl <myspider>
这就相当于用Scrapyd启动了对应项目的一个Spider。
示例响应:
1 | {"status": "ok", "jobid": "6487ec79947edab326d6db28a2d86511e8247444"} |
cancel.json
这个接口可以用来取消某个爬虫任务。
示例请求:
1 | curl http://localhost:6800/cancel.json -d project=<myproject> -d job=6487ec79947edab326d6db28a2d86511e8247444 |
示例响应:
1 | {"status": "ok", "prevstate": "running"} |
listprojects.json
这个接口用来列出部署到Scrapyd服务上的所有项目的描述信息。
示例请求:
1 | curl http://localhost:6800/listprojects.json |
示例响应:
1 | {"status": "ok", "projects": ["myproject", "otherproject"]} |
listversions.json
这个接口用来获取某个项目可用的版本列表。
示例请求:
1 | curl http://localhost:6800/listversions.json?project=myproject |
示例响应:
1 | {"status": "ok", "versions": ["V1", "V2"]} |
listspiders.json
这个接口用来获取某个项目的最后一个(除非被覆盖)版本中可用的Spider名称。
示例请求:
1 | curl http://localhost:6800/listspiders.json?project=<myproject> |
示例响应:
1 | {"status": "ok", "spiders": ["spider1", "spider2", "spider3"]} |
listjobs.json
这个接口获取某个项目的待处理、正在运行和已完成作业的列表详情。
示例请求:
1 | curl http://localhost:6800/listjobs.json?project=<myproject> |
示例响应:
1 | { |
delversion.json
删除项目版本。
示例请求:
1 | curl http://localhost:6800/delversion.json -d project=<myproject> -d version=V1 |
示例响应:
1 | {"status": "ok"} |
delproject.json
删除项目及其所有上传的版本。
示例请求:
1 | curl http://localhost:6800/delproject.json -d project=<myproject> |
示例响应:
1 | {"status": "ok"} |
Scrapyd-Client
Scrapyd提供了一系列API来帮助实现Scrapy项目的管理,不过这对于部署来说并不方便,即如何将Scrapy项目部署到Scrapyd上。一般而言,部署的这个过程需要将项目打包成egg文件,可是这个打包过程,其实还是比较繁琐。这里使用现成的工具来实现部署:Scrapyd-Client。
Scrapyd-Client提供两个功能:
- 将项目打包成egg文件;
- 将打包生成egg文件通过addversion.json接口部署到Scrapyd上。
Scrapyd-Client安装命令:pip3 install scrapyd-client
Scrapyd-Client部署
要部署Scrapy项目,首先需要修改一下项目的配置文件。在scrapy项目的第一层会有一个scrapy.cfg文件,将其内容修改为:
1 | [settings] |
然后在scrapy.cfg文件所在路径下执行命令:scrapy-deploy
如果有多台主机,我们可以配置各台主机的别名,例如可以修改配置文件为:
1 | [settings] |
有多台主机就在此统一配置,一台主机对应一组配置在deploy后面加上主机的别名即可。如想将项目部署到IP为192.168.2.5的vm3主机上,
只需要执行:scrapyd-deploy vm3
Scrapyd-API
ScrapydAPI安装命令:pip3 install python-scrapyd-api
上面解决了部署问题。如果我们想实时看到服务器上 Scrapy 的运行状态怎么办?正如我之前所说,当然,我请求的是 Scrapyd 的 API。如果我们想用Python程序来控制呢?我们还使用requests库来一次又一次地请求这些API?这太麻烦了,所以为了解决这个需求,Scrapyd-API又出现了,有了它我们只需要简单的Python代码就可以监控和运行Scrapy项目了:
1 | From scrapyd_api import ScrapydAPI |
这个返回的结果就是每个Scrapy项目的运行。例如:
1 | { |
这样我们就可以看到Scrapy爬虫的运行状态。
所以,有了他们,我们可以完成的是:
- 使用 Scrapyd 完成 Scrapy 项目的部署
- 通过 Scrapyd 提供的 API 控制 Scrapy 项目的启动和状态监控
- 使用 Scrapyd-Client 简化 Scrapy 项目的部署
- 通过 Scrapyd-API 通过 Python 控制 Scrapy 项目
Gerapy 爬虫管理框架的使用
上述部署过程实现起来真的很方便吗?当然不是!如果这一切,从Scrapy的部署、启动到监控、查看日志,我们只需要点几下鼠标和键盘就可以完成,是不是很美?另外,我们可以直观的配置各种定时任务和监控功能,方便调度Scrapy爬虫项目。或者,即使是 Scrapy 代码也可以自动为您生成它,不是很酷吗?
因此,Gerapy诞生了。
Gerapy 是一个支持 Python 3 的分布式爬虫管理框架,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Django、Vue.js。Gerapy 可以帮助我们:
- 更方便的履带运行控制
- 更直观地查看爬虫状态
- 更实时地查看爬取结果
- 更轻松的计时任务
- 更轻松的项目部署
- 更统一的主机管理
- 更轻松地编写爬虫代码
有了它,Scrapy分布式爬虫项目的管理不再困难。
安装命令:pip3 install -U gerapy
Gerapy使用说明
初始化
利用gerapy命令新建一个工作目录:
1 | gerapy init |
这将在当前目录中生成一个 gerapy 文件夹。这个 gerapy 文件夹是 Gerapy 的工作目录。进入gerapy文件夹后,会发现两个文件夹:
- projects ,用于存储 Scrapy 爬虫项目。
- logs,用于存储 Gerapy 运行日志。
数据库配置
Gerapy使用数据库来存储各种项目配置、定时任务等,所以第二步就是初始化数据库。
首先进入工作目录,例如工作目录名称为gerapy,执行如下命令:
1 | cd gerapy |
此时,首先初始化数据库,执行如下命令:
1 | gerapy migrate |
这将生成一个 SQLite 数据库,该数据库将用于保存每个主机的配置信息、部署版本、定时任务等。
这时候,你可以在工作目录中找到另一个文件夹:
- dbs,用于存储 Gerapy 运行时所需的数据库。
新用户
Gerapy默认开启了登录认证,所以在启动服务前需要设置一个admin用户。
为方便起见,您可以直接使用初始管理员的命令快速创建管理员管理员。密码也是admin。命令如下:
1 | gerapy initadmin |
如果不想直接创建管理员用户,也可以使用以下命令手动创建管理员用户:
1 | gerapy createsuperuser |
此时Gerapy会提示我们输入用户名、邮箱、密码等,然后用这个用户登录Gerapy。
启动服务
接下来启动Gerapy服务,命令如下:
1 | gerapy runserver |
这将在默认的 8000 端口上打开 Gerapy 服务。
这时候在浏览器中打开http://localhost:8000进入Gerapy。
首先Gerapy会提示用户登录,页面如下:

输入您在上一步中创建的用户名和密码,进入 Gerapy 的主页:

如果您希望 Gerapy 在公共环境中运行,您可以像这样指定主机和端口:
然后可以通过8000端口从公共访问Gerapy。
如果你想让 Gerapy 在守护进程中运行,你可以像这样运行:
1 | gerapy runserver 0.0.0.0:8000 > /dev/null 2>&1 & |
然后 Gerapy 将在守护进程和公共环境中运行。
主机管理
在主机管理中,我们可以添加每个主机的 Scrapyd 运行地址和端口并命名。添加后会出现在主机列表中。Gerapy会监控每台主机的运行状态,并在不同的状态下对其进行识别:

添加后,我们可以轻松查看和控制每个主机正在运行的爬虫任务。
项目管理
上面还提到了Gerapy的工作目录下有一个空的projects文件夹,也就是存放Scrapy目录的文件夹。
如果我们要部署 Scrapy 项目,只需将项目文件放在项目文件夹中即可。
例如,您可以将项目放入项目文件夹中,如下所示:
- 将本地 Scrapy 项目直接移动或复制到项目文件夹中。
- 克隆或下载远程项目,例如 Git Clone,然后将项目下载到项目文件夹。
- 通过软连接将项目链接到项目文件夹(在 Linux、Mac 下使用 ln 命令,使用 mklink 命令)。
比如这里的项目中放两个Scrapy项目:

然后回到Gerapy管理界面,点击Project Management可以看到当前的项目列表:

由于项目这里有打包和部署记录,所以这里单独展示。
另外,Gerapy提供了项目在线编辑功能,我们可以通过点击编辑直观地编辑项目:

如果项目没有问题,可以点击部署进行打包部署。您需要在部署之前打包项目。打包时可以指定版本说明:

打包完成后,可以点击部署按钮,将打包好的Scrapy项目部署到对应的云主机上,也可以批量部署。

部署完成后,您可以返回主机管理页面安排任务。单击“调度”以查看任务管理页面。可以查看当前主机上所有任务的运行状态:

我们可以通过点击运行、停止等按钮来启动和停止任务,也可以通过展开任务条目来查看日志详情。
这样我们就可以实时看到每个任务的状态。
定时任务
另外,Gerapy支持设置定时任务,进入任务管理页面,新建定时任务,比如新建一个crontab模式,每分钟运行一次:

在这里,如果设置每分钟运行一次,可以将“分钟”设置为1,可以设置开始日期和结束日期。
创建完成后,返回任务管理首页,可以看到已创建的定时任务列表:

点击“状态”查看当前任务的运行状态:

还可以通过单击右上角的计划按钮手动控制计划任务并查看运行日志。
参考网址:
- https://scrapyd.readthedocs.io/en/stable/api.html
- https://cuiqingcai.com/31049.html
- https://docs.gerapy.com/en/latest/usage.html
- https://scrapyd.readthedocs.io/en/stable/api.html#addversion-json
*Docker部署Scrapy项目
随着容器化技术的发展,Dcoker+Kubernetes的解决方案变得越来越流行,Kubernetes已成了最主流的容器化编排工具。接下来就来了解一下Scrapy项目的另外一种部署方式:基于Docker+Kubernetes的部署和维护方案,具体有以下几点:
- 如何把Scrapy项目打包成一个Docker镜像?
- 如何利用Dcoker Compose来方便的维护和打包镜像?
- 如何使用Kubernetes来部署Scrapy项目的Docker镜像?
- 如何监控Scrapy项目的爬取状态?
打包Scrapy成Dcoker镜像
本节将以ScrapyCompositeDemo项目打包成一个Docker镜像,代码见https://github.com/Python3WebSpider/ScrapyCompositeDemo/tree/scrapy-redis
可直接克隆代码命令:git clone -b scrapy-redis https://github.com/Python3WebSpider/ScrapyCompositeDemo.git
这里需要确保Docker已安装,同时项目中的代理池和账号池也需要配好且可运行。
创建Dockerfile
首先在项目的根目录下创建一个requirements.txt文件,将整个项目依赖的Python环境包都列出来,如下所示:
1 | scrapy |
然后在项目根目录下新建一个Dockerfile文件,将其内容修改为:
1 | FROM python:3.7 |
第一行的FROM代表使用的Docker基础镜像,这里我们直接使用python3.7的镜像,在基础上运行Scrapy项目;
第二行的WORKDIR是运行路径,将其设置为/app,这样在Docker中,最终运行程序所在的路径就是/app;
第三行的COPY是将本地的requirements.txt复制到Docker的工作路径下,即复制到/app下;
第四行的RUN运行了pip命令,用来读取上一步复制到Docker工作路径下的requirements.txt,并安装相关依赖库;
第五行的COPY是将当前文件夹下所有的文件复制到Docker的/app路径下。这里之所以不在第三行一起进行复制而是再复制一次是因为这样可以单独将较为耗时构建的安装步骤独立为Docker镜像单独的层级,这样的话,只要requirements.txt不变,以后再构建Docker镜像时,就会直接利用已经构建的层级,不会再耗时构建。
第六行的CMD是容器启动命令。在容器运行时,此命令会被执行,这里直接用scrapy crawl book来启动。
改用环境变量
由于对接的是Docker,所以需要修改几处代码,如账号池的API地址以及Redis连接地址,之前是写死在代码中的,在构建了Docker镜像后,这些定义建议改成环境变量的形式。
在middlewares.py文件中,修改accountpool_url 和proxypool_url 变量的定义:
1 | import os |
另外在settings.py中,REDIS_URL的定义也需要改成环境变量的获取方式,具体如下:
1 | REDIS_URL = os.getenv('REDIS_URL') |
Docker构建镜像
构建镜像的相关命令如下:
1 | docker build -t scrapycompositedemo . |
其中的’.’代表当前目录,构建完成后可以使用命令docker images查看镜像。
Docker 运行镜像
运行镜像时,如需要先指定环境变量,可以新建一个.env文件,其内容如下:
1 | ACCOUNTPOOL_URL = http://host.docker.internal:6777/antispider7/random |
这里定义了三个环境变量,分别是账号池、代理池、Redis数据库的连接地址,其中每个变量的host都是host.docker.internal,这代表Docker所在宿主机的IP地址,通过host.docker.internal,在Docker内部便可以访问宿主机的相关资源。
本地测试运行,可以执行命令:docker run --env-file .env scrapycompositedemo
推送至Docker Hub
构建完成之后,可以将镜像推送至Docker镜像托管平台,如Docker Hub或私有的Docker Registry等,这样就可以从远程服务器拉镜像并运行了。以Docker Hub为例,如果项目包含一些私有的连接信息(如数据库),最好将Repository设为私有的Registry或直接放到私有的Docker Registry。
登录Docker Hub命令:docker login,输入用户名密码后就完成登录了。
为新建的镜像打标签,命令如下:
1 | docker tag scrapycompositedemo:latest germey/scrapycompositedemo:latest |
推送镜像至Docker Hub即可,命令如下:
1 | docker push germey/scrapycompositedemo |
此时Docker Hub便会出现新推送的Docker镜像了。
如果想在其他主机上运行镜像,在主机上安装好Docker,运行的代理池、账号池、Redis数据库后,按照同样的方式新建.env文件,可以直接执行如下命令:
docker run --env-file .env germey/scrapycompositedemo
这样就会自动下载所推送的镜像,然后读取环境变量并运行了。
参考网址:https://yeasy.gitbook.io/docker_practice/install/mirror
Docker Compose的使用
上一小节了解了将Scrpay项目打包成Docker镜像的方式,不过其中还有一些不方便的点:
- 构建镜像的命令比较繁琐,如需要添加一些额外配置选项;
- 如果需要同时启动多个Docker容器协同运行,仅使用docker run命令是难以实现的;
Docker Compose是用于定义运行多容器Docker应用程序的工具。通过它,可以使用YAML格式的文件,来配置程序所需要的所有服务,比如YAML文件里面定义了构建的目标镜像名称、容器启动的端口、环境变量设置等,把这些固定的内容配置到YAML后,只需要简单的docker-compose命令就可以实现镜像的构建和容器的启动了。
创建YAML文件
确保相关代理池、账号池正常运行后后,在ScrapyCompositeDemo根目录下创建docker-compose.yam文件,内容如下:
1 | version: "3" |
首先第一行我们指定了version,其值为3,即Docker Compose版本信息;
然后指定了services的配置,一个是redis数据库,一个是scrapycompositedemo爬虫项目;
对于redis来说,直接使用已有的公开镜像,指定了container_name,即redis:alpine启动后的容器名称,直接赋值为redis,最后指定了端口号6379;
对于Scrapy爬虫项目来说,由于代码在本地,构建位置就指定为’.’,然后指定构建的目标镜像名称,利用环境变量environment来指定环境变量,最后还指定了depends_on配置,内容为redis,即该容器的启动需要依赖于刚声明的redis服务,这样只有等redis对应的容器正常启动后该容器才会启动。
Docker compose构建镜像
利用docker compose命令构建Dcoker镜像,在docker-compose.yaml目录下运行该命令:docker-compose build
这里和上一小节的构建过程非常类似,只是我们不再关心怎么样指定镜像名称,不用指定构建路径了。
Docker compose运行镜像
docker compose运行镜像也是十分简单的,无须指定环境变量、容器名称、容器运行端口等内容,只需要一条命令就可以启动redis和scrapycompositedemo这两个服务:
1 | docker-compose up |
启动后查看日志就可以发现,首先启动redis,然后创建scrapycompositedemo这个服务,接着运行了Scrapy爬虫项目并开始爬取相应的数据。
Docker compose推送镜像
如果在本地测试镜像没有问题,则可以推送镜像到Docker Hub或其他Docker Registry服务上。使用命令:
1 | docker-compose push |
执行完后,指定的镜像就可以被推送到Docker Hub供其他主机下载运行了。
参考网址:
- Yaml文件格式:https://www.runoob.com/w3cnote/yaml-intro.html
*Kubernetes的使用
前面已经介绍了Dcoker镜像的搭建过程以及Docker Compose的使用,但是这个距离大规模的运维还有以下几点不足:
- 如何快速部署几十、上百、上千个爬虫程序并协同爬取?
- 如何实现爬虫的批量更新?
- 如何实时查看爬虫的运行状态和日志?
Kubernetes,又被简称作 K8s(K 和 s 中间含有 8 个字母),它是用于编排容器化应用程序的云原生系统。Kubernetes 诞生自 Google,现在已经由 CNCF (云原生计算基金会)维护更新。Kubernetes 是目前最受欢迎的集群管理方案之一,可以非常容易地实现容器的管理编排。
最常见的容器技术就是 Docker 了,容器它提供了相比传统虚拟化技术更轻量级的机制来创建隔离的应用程序的运行环境。比如对于某个应用程序,我们使用容器运行时,不必担心它与宿主机之间产生资源冲突,不必担心多个容器之间产生资源冲突。同时借助于容器技术,我们还能更好地保证开发环境和生产环境的运行一致性。另外由于每个容器都是独立的,因此可以将多个容器运行在同一台宿主机上,以提高宿主机资源利用率,从而也进一步降低了成本。总之,使用容器带来的好处很多,可以为我们带来极大的便利。
不过单单依靠容器技术并不能解决所有的问题,也可以说容器技术也引入了新的问题,比如说:
- 如果容器突然运行异常了怎么办?
- 如果容器所在的宿主机突然运行异常了怎么办?
- 如果有多个容器,它们之间怎么有效地传输数据?
- 如果单个容器达到了瓶颈,如何平稳且有效地进行扩容?
- 如果生产环境是由多台主机组成的,我们怎样更好地决定使用哪台主机来运行哪个容器?
以上列举了一些单纯依靠容器技术或者单纯依靠 Docker 不能解决的问题,而 Kubernetes 作为容器编排平台,提供了一个可弹性运行的分布式系统框架,各个容器可以运行在 Kubernetes 平台上,容器的管理、调度、部署、扩容等各个操作都可以经由 Kubernetes 来有效实现。比如说,Kubernetes 可以管理单个容器的声明周期,并且可以根据需要来扩展和释放资源,如果某个容器意外关闭,Kubernetes 可以根据对应的策略选择重启该容器,以保证服务的正常运行。
Kubernetes的相关概念
这里介绍几个Kubernetes中的重要概念,包括Node、Namespace、Pod、Deployment、Service、Ingress等等。
Node
Node,即节点,在Kubernetes中,节点就意味着容器运行的宿主机。Node又分为Master Node、Worker Node,其中Master Node可以认为是集群的管理节点,负责管理整个集群,并提供集群的数据访问入口,其上运行着一些核心组件,如API Server负责接收API指令,Controller Manager负责维护集群的状态等。
Node是Pod真正运行的主机,可以是物理机,也可以是虚拟机。为了管理Pod,每个Node节点上至少要运行container runtime(比如docker或者rkt)、kubelet和kube-proxy服务。
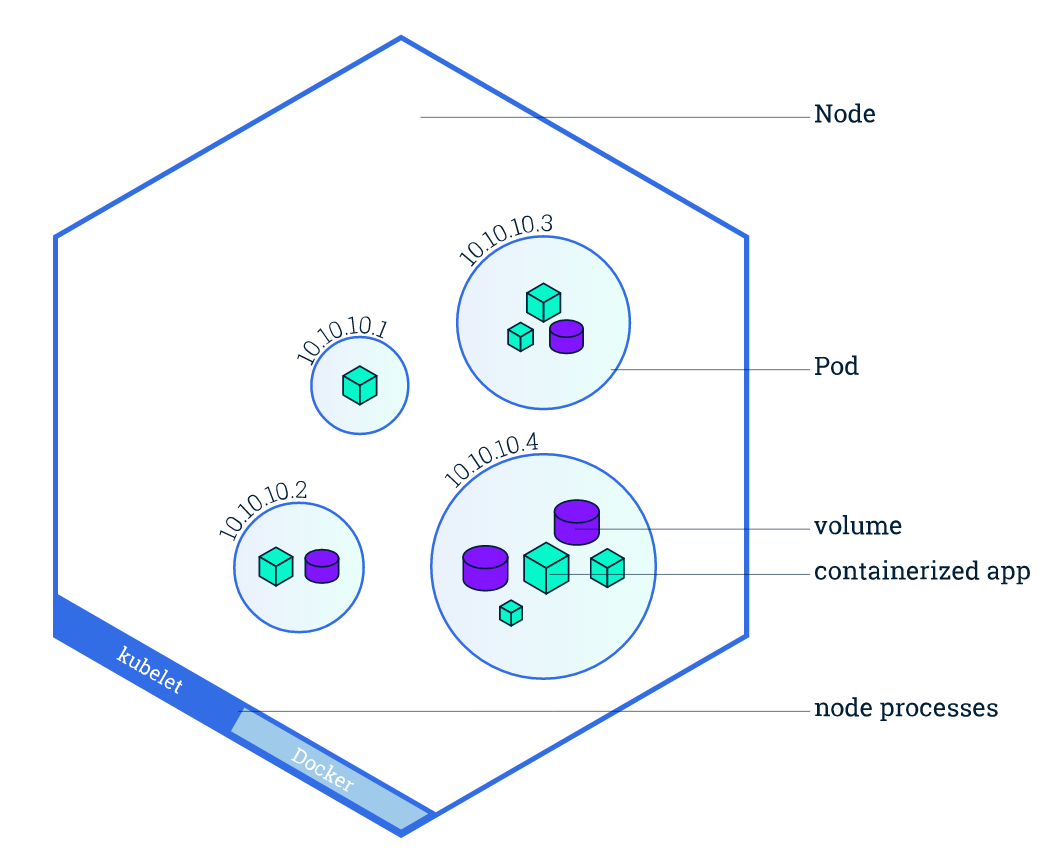
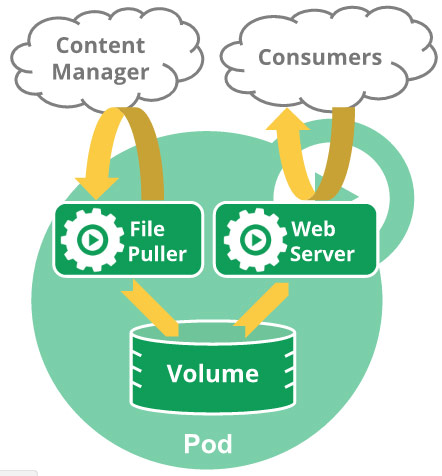
Pod
在Kubernetes中,最小的管理元素不是一个个独立的容器,而是Pod,Pod是最小的,管理,创建,计划的最小单元。
一个Pod相当于一个共享context的配置组,在同一个context下,应用可能还会有独立的cgroup隔离机制,一个Pod是一个容器环境下的“逻辑主机”,它可能包含一个或者多个紧密相连的应用,这些应用可能是在同一个物理主机或虚拟机上,同一个Pod里面的容器可以共享资源、网络、存储系统。,
通常情况下,我们不会单独的显示地创建Pod对象,而是会借助于Deployment等对象来创建。
Deployment
Deployment,即部署。利用它可以定义Pod的配置,如副本、镜像、运行所需要的资源等。
Deployment在Pod和ReplicaSet之上,提供了一个声明式定义方法,比如我们声明一个Deployment并指定Pod副本数量为2,应用该Deployment之后,Kubernetes便会为我们创建两个Pod。因此只需要在Deployment中描述你想要的目标状态是什么,Deployment controller就会帮你将Pod和Replica Set的实际状态改变到你的目标状态。
比如一个简单的nginx应用可以定义为:
1 | apiVersion: extensions/v1beta1 |
Service
如果一个服务,在部署的时候声明了副本数量为2,即创建两个Pod,每个Pod都有自己在Kubernetes中的IP地址并在对应的端口上启动了服务,但这一组Pod服务怎么统一暴露给Kubernetes之外来访问呢?这就引入了Service的概念。
service是将运行在一组Pod上的应用程序公开为网络服务的抽象机制。Service相当于一个负载均衡器,通过一些定义可以找到关联的一组Pod,当请求到来时,它可以将流量转发到对应的任一Pod上进行处理。
Ingress
Ingress用于对外暴露服务,该资源对象定义了不同的主机名(域名)及URL和对应后端Service的绑定,根据不同的路径路由HTTP和HTTPS流量。比如通过Ingress,我们可以配置哪个域名对应的流量转发到哪个Service上,还可以配置一些HTTPS证书相关的内容。
Kubernetes案例上手
该示例是基于Docker自带的Kubernetes集群实现的,安装好Docker之后,在Docker的设置面板中勾选Enable Kubernetes即可在本地开启一个Kubernetes。
注意kubectl需要提前安装好,参考:https://kubernetes.io/zh/docs/tasks/tools/
Docker Desktop创建的Kubernetes的Context名称叫做Kubernetes,切换Kubernetes Context为本地的Kubernetes:
1 | kubectl config use-context docker-desktop |
可以使用kubectl命令查看Kubernetes集群的运行状态:
1 | # 查看节点信息 |
如上操作均未报错说明Kubernetes已经创建好了。
Docker镜像示例
这时候创建一个示例Docker镜像。新建一个文件夹名为app并将其当作工作目录,在该目录下创建一个main.py文件,文件内容如下:
1 | from fastapi import FastAPI |
这是基于FastAPI编写的一个服务,然后在app同级目录下创建一个Dockerfile,其内容如下:
1 | FROM python:3.7 |
接下来,在Dockerfile所在文件夹下运行命令创建一个Dockerfile镜像,
1 | docker build -t testserver . |
这样子镜像就构建好了,运行一下试试:
1 | docker run -p 8888:80 testserver |
这里运行了当前镜像,启动了一个容器,容器本身是在80端口运行的。由于设置了端口映射,将宿主机的8888端口转发到了80端口,因此在浏览器中打开 http://localhost:8888/,可看到输出"Hello World”。
接下来把镜像推送到Docker Hub。先修改镜像名称,然后推送即可,
1 | docker tag testserver germey/testserver # germey是指用户名 |
Kubernetes部署示例
推送成功后,创建一个YAML文件,叫做deployment.yaml,其内容如下:
1 | apiVersion: apps/v1 |
这里定义了一个Deployment对象,一些配置信息如下:
metadata定义了Deployment的基本信息:
- name:Deployment的名称;
- namespace:命名空间,这里使用上一步新创建的service
- labels:声明一些标签,健值对的形式,它旨在用于指定对用户有意义且相关的对象的标识属性。
spec声明Deployment对象对应的Pod基本信息:
- replicas: 这里指定为3,这就声明了需要创建三个Pod,即创建三个Pod副本;
- selector: 声明了该Deployment如何查找要管理的Pod,这里通过matchlabels指定了一个键值对,这样符合该键值对的Pod就归属该Deplyment管理。
- template: 声明了Pod里面运行的容器的信息,其中metadata里面声明了Pod的labels,这和上述selector的matchlabels匹配即可。containers字段指定运行容器的配置,其中包括容器名称、使用的镜像、容器运行端口等。
通过如上配置,就完成了Deployment的声明,现在执行一下部署:
1 | kubectl apply -f deployment.yaml |
接着可以查看Pod的运行状态:
1 | kubectl get pod -n service # -n 表示指定命名空间 |
接下来,声明一个Service对象,再创建一个service.yaml文件,内容如下:
1 | apiVersion: v1 |
metadata定义了Service的基本信息:
- name:Service的名称,可以任意取,只要在一个namespace下不冲突即可;
- namespace:命名空间,这里使用上一步新创建的service
spec声明Service对象对应的Pod基本信息:
- selector: 声明了该Service如何查找要关联的Pod,这里通过selector指定了一个键值对,这样所有带有app为testserver标签的Pod都会被关联到这个Service上。
- ports: protocol声明了该Service和Pod的通讯协议,port指明了Service的运行端口,targetPort指的是Pod内容器的运行端口。
然后部署这个Service对象,命令如下:
1 | kubectl apply -f service.yaml |
创建成功后,我们仍然不能访问这个Service。如果要访问,可以通过端口转发的方式将服务端口映射到宿主机,或修改Service相关的配置,把Service的类型修改为NodePort或者将Service进一步通过Ingress暴露出来。使用端口转发的方式将Kubernetes中的Service转发到本机的某个端口上:
1 | kubectl port-forward service/testserver 9999:8888 -n service |
这里将宿主机的9999端口转发到Service的8888端口,这样在本地访问9999端口就相当于访问Kubernetes的Service的8888端口。因此在浏览器中打开http://localhost:9999/,可看到输出'Hello World’。
参考网址:
- https://kubernetes.io/zh/docs/concepts/overview/what-is-kubernetes/
- https://cuiqingcai.com/31100.html
*用Kubernetes部署和管理Scrapy爬虫
了解了Kubernetes的基本操作,这里进行一个实战练习,将代理池、账号池、Scrapy爬虫项目部署到Kubernetes集群上来运行。
新建一个kubernetes,在该文件夹下,创建多个Kubernetes的YAML部署文件用于资源部署。
Namespace
新建一个Namespace,叫做crawler,将所有资源都部署到这个Namespace下,创建Namespace的命令如下:
1 | kubectl create namespace crawler |
Redis
这里可以先进行Redis数据库的部署,因为代理池、账号池、Scrapy爬虫项目均是以Redis为基础。
部署一个最基础的单实例Redis数据库,首先在kubernetes文件夹下新建一个redis文件夹,再在redis文件夹中创建一个deployment.yaml文件,其内容如下:
1 | apiVersion: apps/v1 |
上述声明了一个Deployment,并在containers字段里使用该镜像redis:alpine进行部署,端口设置6379。
接着在redis文件夹中创建一个service.yaml文件,其内容如下:
1 | apiVersion: v1 |
这里Service同样声明6379端口,targetPort需要和Deployment的containerPort对应,也就是6379。
接下来切换至redis的上一级目录,执行命令:
1 | kubectl apply -f redis |
Redis数据库就部署成功后用如下命令查看部署状态:
1 | kubectl get deployment/redis -n crawler |
如需部署Redis集群,推荐使用Helm部署Redis,参考:https://github.com/bitnami/charts/tree/master/bitnami/redis
代理池
在kubernetes文件夹下新建proxypool文件夹,在proxypool文件夹内新建deployment.yaml文件,其内容如下:
1 | apiVersion: apps/v1 |
和Redis的Deployment声明类似,值得注意的是这里通过env声明了两个环境变量,指定了Redis的链接地址,REDIS_HOST的值是’redis.crawler.svc.cluster.local’,该值是Kuberbetes根据部署的Service和Namespace名称自动生成的,其格式是<service-name>.<namespace-name>.svc.<cluster-domain>。一般情况下,cluster-domain的值为cluster.local,此时的Namespace为crawler,Redis的Service名称为redis,所以结果就是’redis.crawler.svc.cluster.local’。在Kubernetes其他容器里,可以通过这样的Host访问其他容器。
接下来,创建一个对应的Service,在proxypool文件夹下创建service.yaml,其内容如下:
1 | apiVersion: v1 |
这里声明了Service的运行端口,还是5555,targetPort需要和Deployment的containerPort对应,也是5555。
接着执行如下命令进行部署:
1 | kubectl apply -f proxypool |
proxypool就部署成功后用如下命令查看部署状态:
1 | kubectl get deployment/proxypool -n crawler |
此时可以通过kubetcl的port-forward命令将Kubernetes里面服务转发到本地测试,执行如下命令:
1 | kubetcl port-forward svc/proxypool 8888:5555 -n crawler |
port-forward命令会创建本地和Kubernetes服务的端口映射,这里指定了转发的服务为svc/proxypool,svc就是Service的意思,端口映射配置8888:5555,是指Service运行的5555端口将其转发到本地的8888端口上。
运行上述命令后,在本机浏览器打开http://localhost:8888/random,就可以直接访问代理池的API服务了。
账号池
账号池和代理池的部署非常相似,在kubernetes文件夹下创建accountpool文件夹,在accountpool文件夹下创建deployment.yaml文件,其内容如下:
1 | apiVersion: apps/v1 |
这里指定了REDIS_HOST和REDIS_PORT,同时额外指定了API_PORT和WEBSITE这两个环境变量,并设置了containerPort为6777。
接着创建Service.yaml文件,其内容如下:
1 | apiVersion: v1 |
指定Service的运行端口为6777。
接着执行如下命令进行部署:
1 | kubectl apply -f accountpool |
同样的,将账号池服务转发到本地进行验证:
1 | kbuectl port-forward svc/accountpool 7777:6777 -n crawler |
最后在本机的浏览器打开http://localhost:7777/antispider7/random,如果能正常获取到结果,就说明账号池正常运行。
爬虫项目
因为爬虫项目依赖账号池和代理池,所以在这里我们最后才进行部署。在kubernetes文件下创建scrapycompositedemo文件夹,并在此文件夹下创建deployment.yaml文件,其内容如下:
1 | apiVersion: apps/v1 |
这里配置了germey/scrapycompositedemo为镜像,同时配置了ACCOUNTPOOL_URL、PROXYPOOL_URL、REDIS_URL,这里的Host都设定了redis.crawler.svc.clutser.local,端口都是各个服务的运行端口。
因为Scrapy爬虫项目并不需要提供HTTP服务,这里只需要配置Deployment即可。
接着运行如下命令部署:
1 | kubectl apply -f scrapycompositedemo |
部署完成后执行如下命令查看部署状态:
1 | # 查看部署状态 |
参考网址:
- https://github.com/Python3WebSpider/ScrapyCompositeDemo/tree/docker/kubernetes

