
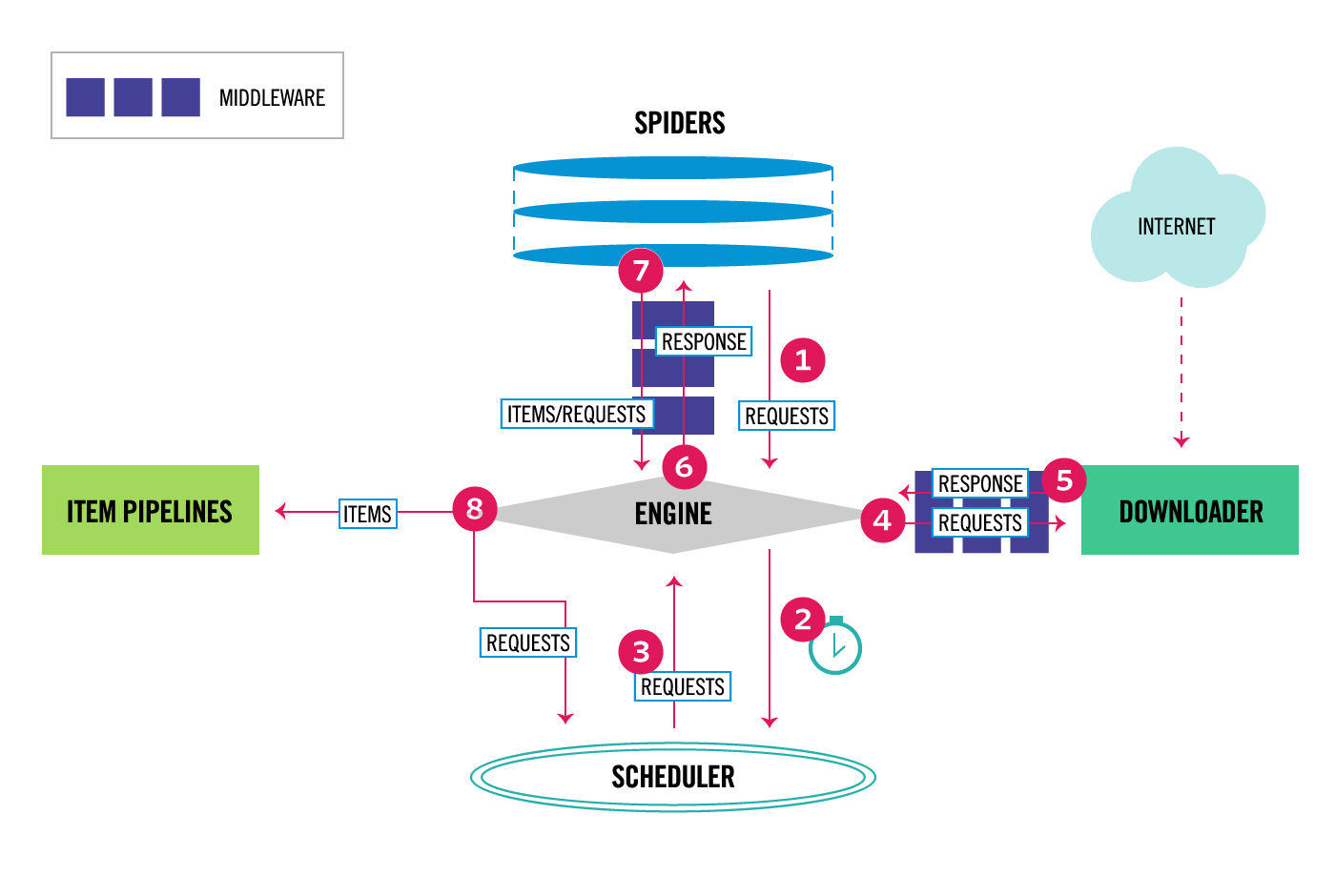
Scrapy架构
Scrapy架构
Selector的使用
Selector是Scrapy内置的数据提取方法,Selector基于parsel库来构建的,而parsel又依赖于lxml,Selector对parsel进行了封装,使其能更好地与Scrapy结合使用,Selector支持Xpath选择器、CSS选择器以及正则表达式。
Selector直接使用
1 | from scrapy import Selector |
Scrapy中的使用
Selector主要是与Scrapy结合使用,如Scrapy的回调函数中的参数response直接调用xpath或css来提取数据。
对于Scrapy中的response对象,response.xpath和response.css等同于response.selector.xpath和response.selector.css;
response对象不能直接调用re和re_first方法,如果要对全文进行正则匹配,可以先调用xpath方法再正则匹配;
Spider类
实现Scrapy项目爬虫,最核心的便是Spider类,它定义了如何爬取缪某个网站的流程和解析方式。
对于Spider类来说,整个爬取过程如此所述:
- 以初始的URL初始话Request并设置回调方法;
- 在回调方法内分析返回的网页内容:返回结果如果是字典或Item对象,可通过Feed Exports形式存入文件;如果是Request,那么Request执行成功后的Response会再次传递给Request中定义的回调方法;
Spider类分析
我们定义的Spider继承自scrapy.spiders.Spider,即scrapy.Spider类,这个类提供了start_requests方法的默认实现,读取并请求start_urls属性,并根据返回的结果调用parse方法解析结果。该类还有一些基础属性:
- name:爬虫名称,定义了Scrapy如何定位并初始化Spider,它必须是唯一的。
- allowed_domains:允许爬取的域名;
- start_urls:起始URL列表;
- custom_settings:专属于本Spider的配置,此设置会覆盖全局的设置;
- crawler:此属性由from_crawler方法设置,代表本Spider类的Crawler对象,其包含了很多项目组件,利用它可以获取项目的一些配置信息;
- settings:一个Settings对象,利用它可以直接获取项目的全局设置变量;
除了一些基础属性,Spider还有一些常用的方法如下:
- start_requests:该方法用于生成初始请求,它必须返回一个可迭代对象,此方法会默认使用start_urls里面的URL来构造Request;
- parse:当Response没有指定回调方法,该方法会默认被调用,该方法需要返回一个包含Request或Item的可迭代对象;
- closed:当Spider关闭时,该方法会被调用。
Downloader Middleware的使用
Downloader Middleware,即下载中间件。它是处于Scrapy的Engine和Downloader之间的处理模块。Downloader Middleware在整个架构中起作用的是一下两个位置:
- Engine从Schedule获取Request发送给Downloader,在Request被Engine发送给Downloader执行下载之前,Downloader Middleware可以对Request进行修改;
- Downloader执行Request后生成Response,在Response被Engine发送给Spider之前,即Response被Spider解析之前,Downloader Middleware可以对Response进行修改;
Downloader Middleware在整个爬虫执行过程都能起到非常重要的作用,功能十分强大,修改User-Agent、处理重定向、设置代理、失败重试、设置Cookie等功能都需要借助它来实现。
默认情况下,Scrapy已经为我们开启了DOWNLOADER_MIDDLEWARES_BASE所定义的Downloader Middleware,比如RetryMiddleware带有自动重试功能,RedirectMiddleware带有自动处理重定向功能。
Downloader Middleware主要是通过定义process_request和process_response方法来分别处理Request和Response。由于Request是由Engine发送给Downloader的,并且优先级数字越小的Downloader Middleware越靠近Engine,所以优先级数字越小的Downloader Middleware的process_request方法越先被调用,process_response方法则相反,由于Response是由Downloader发送给Engine,优先级数字越大的Downloader Middleware越靠近Downloader,所以优先级数字越大的Downloader Middleware的process_response越先被调用。
核心方法
Scrapy内置的Downloader Middleware为Scrapy提供了基础功能,其核心方法有三个:
- process_request(resquest,spider)
- process_response(resquest, response, spider)
- process_exception(resquest, exception, spider)
只需要实现其中至少一个方法,就可以定一个Downloader Middleware。
process_request
Request被Engine发送给Downloader之前,process_request方法就会被调用,也就是Request从Schedule里被调度出来发送给Downloader下载之前,我们可以用process_request方法对Request进行处理。
process_request有两个参数:
- request:Request对象,即被处理request;
- spider:Spider对象,即此request对应的Spider对象
该方法的返回值 必须为None、Response对象、Request对象三者之一,或抛出IgnoreRequest异常;返回类型不同,产生效果也不同:
- 返回None:Scrapy将继续处理该Request,接着执行其他Downloader Middleware的process_request方法,一直到Downloader把Request执行得到Response才结束;
- 返回为Response对象:更低优先级的Downloader Middleware的process_request和process_exception方法就不会被继续调用;每个Downloader Middleware的process_response方法转而被依次调用;
- 返回Request对象:更低优先级的Downloader Middleware的process_request方法会停止执行,这个Request会重新放到调度队列里等待被调度;
- 抛出IgnoreRequest异常:则所有的Downloader Middleware的process_exception方法会依次执行。如果没有方法处理这个异常,则Request的errorback方法就会回调。如果该异常还是未被处理,则会忽略。
process_response
Downloader执行Request下载之后,会得到相应的Response。Engine便会将Response发送给Spider进行解析,在发送给Spider之前,我们可以用process_response方法来对Response进行处理.
process_response有两三个参数:
- request:Request对象,即此Response对应的Request;
- response:Response对象,即被处理的Response
- spider:Spider对象,即此Response对应的Spider对象
该方法process_response的返回值必须为Request对象和Response对象两者之一,或者抛出IgnoreRequest异常;返回类型不同,产生效果也不同:
- 返回为Request对象:更低优先级的Downloader Middleware的process_response方法就不会被继续调用;该Request对象会被重新放到调度队列里等待被调度;
- 返回Response对象:更低优先级的Downloader Middleware的process_response方法会继续调用,对该Response对象进行处理;
- 抛出IgnoreRequest异常:则Request的errorback方法就会回调。如果该异常还是未被处理,则会忽略。
process_exception
当Downloader或process_request方法抛出异常时,process_exception就会被调用。
process_exception有两三个参数:
- request:Request对象,即产生异常的Request;
- exception:Exception对象,即抛出的异常
- spider:Spider对象,即Request对应的Spider对象
该方法process_exception的返回值必须为None,Request对象和Response对象三者之一;返回类型不同,产生效果也不同:
- 返回None:更低优先级的Downloader Middleware的process_exception会被继续顺次调用,直到所有的方法都被调用;
- 返回为Request对象:更低优先级的Downloader Middleware的process_exception方法就不会被继续调用;该Request对象会被重新放到调度队列里等待被调度;
- 返回Response对象:更低优先级的Downloader Middleware的process_exception方法就不会被继续调用,每个Downloader Middleware的process_response方法转而被依次调用;
Spider Middleware的使用
Spider Middleware是处于Spider和Engine之间的处理模块,当Downloader生成Response之后,Response会被发送给Spider,在发送给Spider之前,Response会首先经过Spider Middleware的处理,当Spider处理生成Item和Request之后,Item和Request还会经过Spider Middleware的处理。
Spider Middleware有以下三个作用:
- Download生成Response之后,Engine会将其发送给Spider进行解析,在Response发送给Spider之前,可借助Spider Middleware进行处理;
- Spider生成Request之后会被发送至Engine,然后Request会被转发到Schedule,在Request被发送给Engine之前,可以借助Spider Middleware对Request进行处理;
- Spider生成Item之后会被发送至Engine,然后Item会被转发到Item Pipeline,在Item被发送给Engine之前,可以借助Spider Middleware对Item进行处理;
简言之,Spider Middleware可以用来处理输入给Spider的response和Spider输出的Item以及Request。
默认情况下,Scrapy已经为我们开启了SPIDER_MIDDLEWARES_BASE所定义的SPIDER Middleware,比如HttpErrorMiddleware,OffsiteMiddleware。
这些Spider Middleware的调用优先级和Downloader Middleware类似。数字越小的Spider Middleware越靠近Engine,数字越大的Spider Middleware越靠近Spider。
核心方法
每个Spider Middleware都定义了以下一个或多个方法的类,核心方法有以下四个:
- process_spider_input(response, spider)
- process_spider_output(response, result, spider)
- process_spider_exception(response, exception, spider)
- process_start_requests(start_requests, spider)<
process_spider_input
当Response通过Spider Middleware时,process_spider_input方法被调用,处理该Response有两个参数:
- response:Response对象,即被处理的Response
- spider:Spider对象,即此Response对应的Spider对象
process_spider_input应该返回None或者抛出一个异常:
- 返回None:Scrapy会继续处理该Response,调用所有其他的Spider Middleware直到Spider处理该Response;
- 抛出异常:Scrapy不会调用所有其他的Spider Middleware的process_spider_input方法,并调用Request的errback方法;
process_spider_output
当Spider处理Response返回结果时,process_spider_output方法被调用,它有三个参数:
- response:Response对象,即生成该输出的Response;
- result:包含Request或Item对象的可迭代对象,即Spider返回的结果;
- spider:Spider对象,即结果对应的Spider;
process_spider_output必须返回包含Request或Item对象的可迭代对象;
process_spider_exception
当Spider或Spider Middleware的process_spider_input方法抛出异常时,process_spider_exception方法被调用,它有三个参数:
- response:Response对象,即异常被抛出时被处理的Response;
- exception:Exception对象,被抛出的异常;
- spider:Spider对象,即抛出该异常的Spider对象;
process_spider_exception必须返回None或一个含Request或Item对象的可迭代对象
- 返回None:那么Scrapy将继续处理该异常,调用其他Spider Middleware中的process_spider_exception方法,直到所有Spider Middleware都被调用;
- 返回可迭代对象:则其他的Spider Middleware中的process_spider_output方法被调用,其他的process_spider_exception不会被调用;
process_start_requests
process_start_requests方法以Spider启动的Request为参数被调用,执行的过程类似于process_spider_output,只不过它没有相关联的Response并且必须返回Request。它只有两个参数:
- start_requests:包含Request的可迭代对象,即Start Request;
- spider:Spider对象,即Start Requests所属的Spider;
process_start_requests方法必须返回另一个包含Request对象的可迭代对象。
内置的Spider Middleware
HttpErrorMiddleware
HttpErrorMiddleware的主要作用是过滤我们需要忽略的Response,比如状态码为200~299的会处理,500以上的不会处理,其核心代码如下:
1 | class HttpErrorMiddleware: |
如果要针对一些错误类型的状态码进行处理,可以修改Spider的handle_httpstatus_list属性,也可以修改Request meta的handle_httpstatus_list属性,还可以修改全局settings的HTTPERROR_ALLOWED_CODES。
OffsiteMiddleware
OffsiteMiddleware的主要作用是过滤不符合allowd_domains的Request,Spider里面定义的allowd_domains就是在这个Spider Middleware里生效的,其核心代码如下:
1 | class OffsiteMiddleware: |
OffsiteMiddleware根据Request的dont_filter、url、allowed_domains进行了过滤,如果不符合allowed_domains,就直接输出日志并不返回Request。
UrlLengthMiddleware
UrlLengthMiddleware的主要作用就是根据Request的URL长度对Request进行过滤,如果URL长度过长,该Request就会被忽略,其核心代码如下:
1 | class UrlLengthMiddleware: |
由上可知,如果想要只爬取URL长度小于50的页面,可以配置URLLENGTH_LIMIT=50。
Item Pipeline的使用
Item Pipeline即项目管道,它的调用发生在Spider产生Item之后。当Spider解析完Response,Item会被Engine传递到Item Pipeline,被定义的Item Pipeline组件会顺序被调用,完成一连串的处理过程,比如数据清洗、存储等。
Item Pipeline主要功能:①清洗HTML数据;②验证爬取数据、检查爬取字段;③查重并丢弃重复内容;④将爬取结果存储到数据库;
核心方法
我们可以自定义Item Pipeline,只需要实现指定的方法就好,其中必须实现的一个方法是:process_item(item, spider)
另外还有几个比较实用的方法:
- open_spider(spider)
- close_spider(spider)
- from_crawler(cls, crawler)
process_item
process_item是必须实现的方法,被定义的Item Pipeline会默认调用这个方法进行处理,比如进行数据处理或者将数据库写入数据库等操作。process_item方法的参数有两个:
- item:Item对象,即被处理的Item;
- spider:Spider对象,即生成该Item的Spider;
process_item方法必须返回Item类型或抛出一个DropItem异常。
- 返回Item对象:此item会被低优先级的Item Pipeline的process_item方法处理,直到所有的方法被调用完毕;
- 抛出DropItem异常:此Item就会被丢弃,不再处理;
open_spider
open_spider方法是在Spider开启的时候自动调用的,在这里可以做一些初始化操作,如开启数据库连接等。
close_spider
close_spider方法是在Spider关闭的时候自动调用的,在这里可以做一些收尾工作,如关闭数据库连接。
from_crawler
from_crawler是一个类方法,用@classmethod标识,它接受一个参数crawler。通过crawler对象,我们可以拿到Scrapy的所有核心组件,如全局配置的每个信息,然后在这个方法里创建一个Pipeline实例。参数cls就是Class,最后返回一个Class实例。示例如下:
1 | # MongoDBPipeline |
ImagePipeline
官方文档:https://docs.scrapy.org/en/latest/topics/media-pipeline.html
Scrapy提供了专门处理下载的Pipeline,包括文件下载和图片下载。下载文件和图片的原理与抓取页面的原理一样,因此下载过程支持异步和多线程,十分高效。
在settings.py中添加如下代码可定义存储文件路径:IMAGES_STORE = ‘./images’,Scrapy内置的ImagePipeline会默认读取Item的image_urls字段,并认为它是列表形式,接着遍历该字段后取出每个URL进行图片下载,如Item的图片链接不是image_urls字段表示,则需自定义ImagePipeline继承内置的ImagePipeline,重写以下几个方法:
- get_media_requests(item, info)
- file_path(request, response=None, info=None)
- item_completed(results, item, info)
自定义的ImagePipeline示例如下:
1 | from scrapy import Request |
get_media_requests
该方法第一个参数item是爬取生成的Item对象,上例中我们想要下载的图片链接存储在Item的director和actors的image字段中,因此将URL逐个取出,然后构造成Request发起下载请求。同时指定了meta信息,方便构造图片的存储路径,以便完成时使用。
file_path
该方法第一个参数request就是当前下载对应的Request对象,该方法用来返回保存的文件名。
item_completed
该方法表示单个item完成下载时的处理方法。因为并不是每张图都一定会下载成功,所以需要分析处理并剔除下载失败的图片。
Extension的使用
Scrapy常用组件有Spider、 Downloader Middleware、Spider Middleware、Item Pipeline等,另外还有一个比较实用的组件Extension,利用它可以自定义完成我们想要的功能。
Scrapy提供了一个Extension机制,利用Extension可以注册一些处理方法并监听Scrapy运行过程的各个信号,做到发生某个事件时执行自定义的方法。Scrapy已经内置了一些Extension,如LogStats这个Extension用于记录一些基本爬取信息,比如爬取的页面数,提取的Item数等,Corestats这个Extension用于统计爬取过程中核心统计信息,日开始爬取时间、爬取结束时间等。
和常用组件一样,Extension也是通过settings.py中配置来控制是否被启用的,是通过EXTENSION这个配置来实现的,如下:
1 | EXTENSIONS = { |
如实现自定义的Extension,主要有以下两步:
- 实现一个Python类,然后实现对应的处理方法,如实现一个spider_opened方法用于处理Spider开始爬取时执行的操作,可以接受一个spider参数并对其进行操作;
- 定义from_crawler类方法,利用crawler的signals对象将Scrapy的各个信号和已经定义的处理方法关联起来。
自定义Extension实战
这里尝试利用Extension实现爬取事件的消息通知:在爬取开始时、爬取到数据时、爬取结束时通知指定的服务器,将这些事件和对应的数据通过HTTP请求发送给服务器。
首先用Flask构建一个轻量级的服务器,用于接收POST请求并输出接收到的事件和数据,server.py代码如下:
1 | from flask import Flask, request, jsonify |
接下来在相应的目录下新建一个extensions.py,实现几个对应的事件处理方法,代码如下:
1 | import requests |
这里我们定义一个NotificationExtension类,并实现了三个相应的方法,接着将这些方法和对应的Scrapy信号关联起来。
完成上述定义之后,在settings.py中添加即可启用这个Extension:
1 | EXTENSIONS = { |
Scrapy对接selenium
Scrapy对接selenium原理
自定义一个Downloader Middleware并实现process_request方法,在process_request中我们可以直接获取Request对象的URL,然后在process_request方法中完成使用Selenium请求URL的过程,获取Javascript渲染后的HTML代码,最后把HTML代码构造成HtmlResponse返回即可。这样HtmlResponse就会被传给Spider,Spider拿到的结果就是Javascript渲染后的结果。
Scrapy对接Splash
Scrapy对接Splash和Selenium的原理是不同的,对接Selenium是借助于Downloader Middleware实现的,在Downloader Middleware里,实现了Chrome浏览器渲染页面的过程,并构造HtmlResponse返回给Spider。
而Splash本身就是一个Javascript页面渲染服务,只需要将需要渲染的URL发送给Splash就能得到对用的Javascript渲染结果,而Scrapy-Splash则是提供这个过程基本功能的封装,比如Cookies的处理、URL的转换等。
Splash 的安装:https://cuiqingcai.com/31071.html
Splash 负载均衡配置:https://cuiqingcai.com/31098.html
Scrapy-Splah的配置文档:https://github.com/scrapy-plugins/scrapy-splash#configuration
Scrapy-Splash示例:https://github.com/Python3WebSpider/ScrapySplashDemo/blob/master/scrapysplashdemo/spiders/book.py
由于Splash和Scrapy都支持异步处理,只要Splash能够承受对应的渲染并发量,爬取效率也是不错的。
Scrapy对接Pyppeteer
Scrapy对接Pyppeteer和Selenium的原理是类似的,同样是是借助于Downloader Middleware实现的,最大的不同在于Pyppeteer需要基于asyncio异步执行,这就需要Scrapy对asyncio的支持。
Scrapy对接Pyppeteer原理
Scrapy对接Pyppeteer同样是借助于Downloader Middleware实现的,但是Pyppeteer需要借助asyncio实现异步爬取,即调用的必须是async修饰的方法,虽然Scrapy也支持异步,但其异步是基于Twisted实现的,二者怎么实现兼容呢?从Scrapy2.0开始,Scrapy可以支持asyncio。Twisted的异步对象叫做Deffered,而asyncio的异步对象叫做Future,其支持的原理就是实现了Future到Deffered的转换,代码如下:
1 | import asyncio |
Scrapy提供了一个fromFuture方法,它可以接收一个Future对象,返回一个Deffered对象,另外还需要更换Twisted的Reactor对象,在Scrapy的settings.py中添加如下代码:
1 | TWISTED_REACTOR = 'twisted.internet.asyncioreactor.AsyncioSelectorReactor' |
这样便可以实现Scrapy对Future的异步执行,从而实现Scrapy对asyncio的支持。
Pyppeteer 的安装:https://cuiqingcai.com/31088.html
Pyppeteer 示例:https://github.com/Python3WebSpider/ScrapyPyppeteerDemo/blob/master/scrapypyppeteerdemo/middlewares.py
Scrapy规则化爬虫
在实现Spider的过程中,我们需要定义特定的方法完成一系列操作,比如生成Response、解析Response、生成Item等,整个过程是由代码实现,所以逻辑控制比较灵活,但是可扩展性和可维护性相对比较差。尤其是针对爬取各大站点的新闻内容,考虑使用Scrapy的规则化爬虫。
CrawlSpider
在CrawlSpider里,可以指定特定的爬取规则来实现页面的解析和爬取逻辑,这些规则由一个专门的数据结构Rule表示。
CrawlSpider继承自Spider类,除了Spider类的所有方法和属性,它还提供一个非常重要的属性rules。rules是爬取规则属性,是包含一个或多个Rule对象的列表。CrawlSpider会读取rules的每一个Rule并执行对应的爬取逻辑。它的定义和参数如下:
class scrapy.spiders.Rule(link_extractor=None, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None, errback=None)
各参数如下:
- link_extractor:一个LinkExtractor对象;
- callback:回调方法;
- cb_kwargs:一个字典,定义传递给回调方法的参数;
- follow:布尔值,指定根据该规则从response提取的链接是否需要跟进爬取;
- process_links:用来处理Rule中的link_extractor提取到的链接;
- process_request:根据Rule提取到每个后续Request时,该方法都会被调用,可以进一步对Request处理,必须返回Request对象或者None;
- Errback:当Rule提取出的Request在被处理的过程中发错误时,该方法会被调用;
LinkExtractor
LinkExtractor定义了从Response中提取后续链接的逻辑,在Scrapy中指的就是scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor这个类,为了方便调用,Scrapy定义了一个别名,叫LinkExtractor,二者均是指LxmlLinkExtractor。它的定义和参数如下:
class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), deny_extensions=None, restrict_xpaths=(), restrict_css=(), tags=('a', 'area'), attrs=('href',), canonicalize=False, unique=True, process_value=None, strip=True)
LxmlLinkExtractor接收多个用于提取链接的参数,下面依次对其进行说明:
- allow:一个正则表达式或列表,定义了从当前页面提取出符合规则的链接;
- deny:和allow作用相反,定义了从当前页面禁用提取的链接,相当于黑名单,其优先级高于allow;
- allow_domains:定义了符合规则的域名,只有此域名的链接才会被提取;
- deny_domains:和allow_domains作用相反;
- deny_extensions:定义后缀黑名单,包含这些后缀的链接都不会被提取;其默认值由scrapy.linkextractors.IGNORED_EXTENSIONS变量定义;
- restrict_xpaths:定义Spider从当前页面中Xpath匹配的区域提取;
- restrict_css:定义Spider从当前页面中CSS选择器匹配的区域提取;
- tags:指定从什么节点中提取链接,默认是('a', 'area');
- attrs:指定从节点的什么属性中提取链接,默认是('href'),和tags属性配合起来;
- canonicalize:是否需要对提取到的链接进行规范化处理;
- unique:是否对提取到的链接进行去重;
- process_value:是一个callable方法,可以通过这个方法来定义一个逻辑,这个逻辑负责完成提取提取内容到最终链接的转换;
- strip:是否要去掉首尾空格;
参考网址:
https://docs.scrapy.org/en/latest/topics/link-extractors.html?highlight=LinkExtractor
Item Loaders
Rule并没有对Item的提取方式做规则定义,对于Item的提取,需要借助Item Loaders来实现。
Item Loaders的用法如下所示:
class scrapy.loader.ItemLoader(item=None, selector=None, response=None, **kwargs)
下面依次对Item Loaders的参数进行说明:
- item:Item对象,可以调用add_xpath、add_css等方法来填充Item;
- selector:Selector对象,用来填充数据的选择器;
- resposen:Response对象,用于使用构造选择器的Response;
一个典型的ItemLoader实例如下:
1 | from scrapy.loader import ItemLoader |
这里先声明一个一个Product Item,用该Item和Response对象实例化ItemLoader,调用add_xpath、add_css、add_value方法一次对不同属性赋值,最后调用load_item方法实现对Item的解析。
另外Item Loader的每个字段都包含一个Input Processor和一个Output Processor,利用它们可以灵活地对Item的每个字段进行处理。Input Processor收到数据时立刻提取数据,Input Processor的结果被收集起来并且保存在ItemLoader内,但是不分配给Item。收集到数据后,load_item方法被调用来填充Item对象。在调用时会先调用Output Processor来处理之前收集到的数据,然后再存入Item中,这样就生成了Item。其用法示例如下:
1 | from scrapy.loader import ItemLoader |
像TakeFirst,Join,MapCompose都是Scrapy提供的一些processor,Scrapy已经提供了不少Processor,如下:
Identity
Identity不进行任何处理,直接返回原来的数据
TakeFirst
TakeFirst返回列表的第一个非空值,类似extract_first,常用作Output Processor
Join
Join相当于字符串的join方法
Compose
Compose是使用多个函数组合构造而成的Processor,每个输入值被传递到第一个函数,其输出传递到第二个函数,以此类推,直至最后一个函数返回整个处理器的输出
MapCompose
MapCompose与Compose类似,但MapCompose可以迭代处理一个列表的输入值
SelectJmes
SelectJmes可以查询JSON,传入key,返回查询所得的Value,不过需要先安装jmespath库,示例如下:
1 | from scrapy.loader.processors import SelectJmes |
参考网址:
https://docs.scrapy.org/en/latest/topics/loaders.html
规则化爬虫实战
参考网址:
https://github.com/Python3WebSpider/ScrapyUniversalDemo/tree/master/scrapyuniversaldemo

