
数据可视化理论
数据可视化理论
数据可视化的目的与原则
解释数据+传递信息、压缩信息+突出观点
- 比较两组数据的大小
- 校验两组数据的差异
- 统计随机变量的分布
数据可视化的模式
一般来说,数据可视化的表现形式(模式),有三种:交互式、交互呈现式和呈现式。
- 交互式:用于引导/发现,服务于个体
- 呈现式:用于展示/讲述,服务于群体
数据可视化的对象
一般来说,数据可视化的数据(对象)有三类概念:定量数据、定序数据、定类数据。
- 定量数据(Quantitative):连续、离散 位置> 长度/角度> 面积> 体积> 密度> 颜色
- 定序数据(Ordinal):尺码、态度等 位置> 密度> 颜色> 连接> 包含
- 定类数据(Categorical):城市、品类等 位置> 颜色> 连接> 包含> 形状
上述为优选关系,体现了低维度优选的原则。
其中的密度可以通过疏密程度来体现;颜色主要是通过深浅体现,避免视觉噪声;连接可以用镜头等从属关系来体现有序性。
表现类之间的关系,确保元素清晰。
常用工具包
不基于编程语言:Tableau,Icharts,Infogram,RAW Graphs,…
基于python编程语言:
- Matplotlib:满足基本的需求(用的好可以满足所有的需求,就是用起来太麻烦)
- Seaborn:满足颜控的需求(非常漂亮!非常容易!)
- Bokeh:满足交互呈现的需求
- Plotly:强大的在线交互可视化框架
- Streamlit:专注于机器学习和数据科学团队的用户交互可视化app
数据可视化流程
数据准备
- 数据规模:数据分组、数据采样(处理大数据时尤为需要)
- 数据类型:数值数据、分类数据(一定要对数据结构特别清楚:连续?离散?有序吗?)
- 数据异常:取值异常、数据缺失
确定图表
数据可视化里通常面临的三类问题:
- 关联分析:散点图,曲线图(scatter,plot)
- 分布分析:灰度图,密度图(hist,gaussian_kde,plot)
- 分类分析:柱状图,箱式图(bar,boxplot)
分析迭代
分析迭代主要分为数据拟合、统计学分析。
- 确定拟合模型:OLS, fit OLS = 最小二乘;fit = 拟合
- 分析拟合性能:summary_table统计学汇总
- 确定数据分布:hist
- 确定重点区间:quartile 分布的上下四分位数,以及各分位数之间的区间
输出结论
- 养成看图说话的习惯
- 提出一个好问题,画出一个好图像,给出一个好结论
Matplotlib简介和基本操作
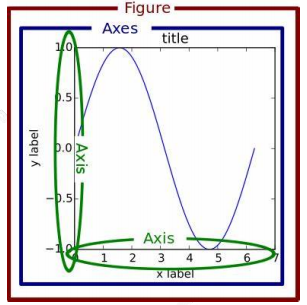
常用设置
获取当前图表对象
1 | fig = matplotlib.pyplot.gcf() |
常用图表对象设置
1 | 例子:有两种设置图像大小的方式,但是有区别!fig.set_size_inches(10,10) # 以英尺为单位 |
保存当前图表对象
1 | matplotlib.pyplot.savefig("figure1.png") |
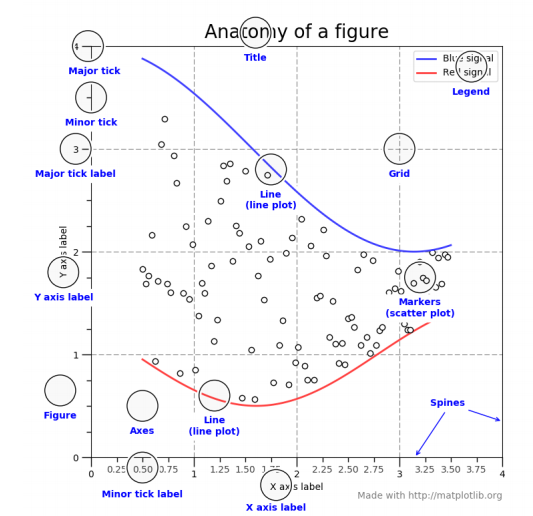
常用图形
- 曲线图:matplotlib.pyplot.plot(data)
- 灰度图:matplotlib.pyplot.hist(data)
- 散点图:matplotlib.pyplot.scatter(data)
- 箱式图:matplotlib.pyplot.boxplot(data)
常用样式
1 | ### 颜色/线型/标记 ### |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 LittleShark's Space!
评论